| Name | Last modified | Size | Description | |
|---|---|---|---|---|
| Parent Directory | - | |||
| shalstab_0.13.py | 2019-05-13 11:51 | 47K | ||
| example_oregon_city/ | 2018-12-19 15:33 | - | ||
| critq2.lyr | 2017-11-09 11:48 | 7.5K | ||
| MFDtest/ | 2019-03-14 12:17 | - | ||
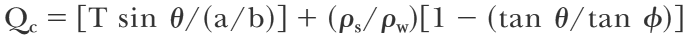
The program holds arrays in memory for (some) speed, and tile size is limited only by the RAM size of the machine on which it is run.
The program can read the same wide variety of raster formats that arcmap supports. Input rasters need to have matching projections and cell size, but do not need matching spatial extent. shalstab.py now depends on the proprietary ESRI arcpy library, but we hope to rewrite it for open source libraries.
shalstab.py uses arcpy functions to convert rasters between esri objects and numpy arrays. Earlier versions required workarounds because the esri codes fails on files larger than 2GB. ArcGIS 10.5.1 is the first version to support larger arrays. You benefits may not be great, as large data sets require much RAM, and run for many days.
An analysis of 18360 16452 cells (5.1°×4.57° on a one-arcsecond DEM) ran for 102 hours on an i7 3.5 GHz computer, using more than 15 GB RAM. The bulk of time is consumed by traversing the array thousands of times, down the valley bottoms to the edge or the sea. The impatient user can get a good result by limiting the number of iterations to the maximum hillslope length, assuming that unprocessed cells are too flat to fail anyway.
The matter of tiling data raises similar issues. Strictly speaking, one cannot get perfect results for a cell if the entire upstream basin is not processed at the same time, but one can get good results if the buffer of overlapping tiles is equal to the hillslope length.
The routing of groundwater on hillsides requires replacement of 8-pointer flow accumulation with what we insist on calling fuzzy flow accumulation. (See illustrations.)
GIS technicians typically fill spurious "sinks" on a DEM, then run an 8-pointer flowdirection algorithm. When the algorithm encounters a flat area, it finds a good-enough path to the pour point. Fuzzy flowaccumulation does not use a flowdirection raster. It must start at the top and distribute flow proportionally to all downhill cells. Then it iterates through the array again, dealing with all the cells that have no upstream contributors. This requires an array with none of the flat spots that are created by filling sinks.
Flat spots have been dealt with by preconditioning the DEM with small slopes. In the 20th-century version of shalstab, flat spots were incrementing upstream from their pour points, one millimeter at a time. When 30m DEM were supplanted by 10m DEMs, we started to find flat spots greater then 1000 cells long, so cells could sometimes be incremented higher than the neighbor cells that flowed into them, causing errors. This problem was reduced by scaling up the (integer) elevations to cover the range of 32-bit integers.
Now that we have floating-point lidar DEMs, we increment flat spots by the smallest possible epsilon, but we still have trouble. As we increment flat cells by hundreds of epsilons, we may encounter an occasional cell that is a millimeter higher than the flat spot, and thus becomes a sink. I try to iterate through the DEM until such minor artifacts are fixed, but I have failed to build a robust algorithm that does not sometimes undertake infinite repairs. That is what happened to Oregon City. This problem can be reduced by using mapped or guessed culverts, but that does not guarantee reliable success. The lyr file can be imported to arcmap to provide an appropriate legend for output data. Click on properties, then on "set data source", then select your own raster object. The flag codes are slightly differnt from those in the aml version.
shalstab.py looks okay, but is not yet certified. And it contains debugging code.
Oregon City example needs to be redone with the current version.
This is a premature draft page. If you have questions, ask Harvey